僕は、Googleが提供するDB、Cloud Firestoreを使用してWEBアプリを開発しました。
ちなみにPWAです。
このWEBアプリは、DBはCloud Firestoreで、会員登録はFirebase Authenticationを使ってます。
Firestoreのデータモデルは特殊で、階層を持つことができる
説明が下手なので、僕のWEBアプリの実例を示します。
僕のWEBアプリは、ユーザ投稿型の会員制サイトです。
ユーザは、単語とその単語の説明文を投稿できます。
このアプリのDBとビューの関連は以下のようになってます。
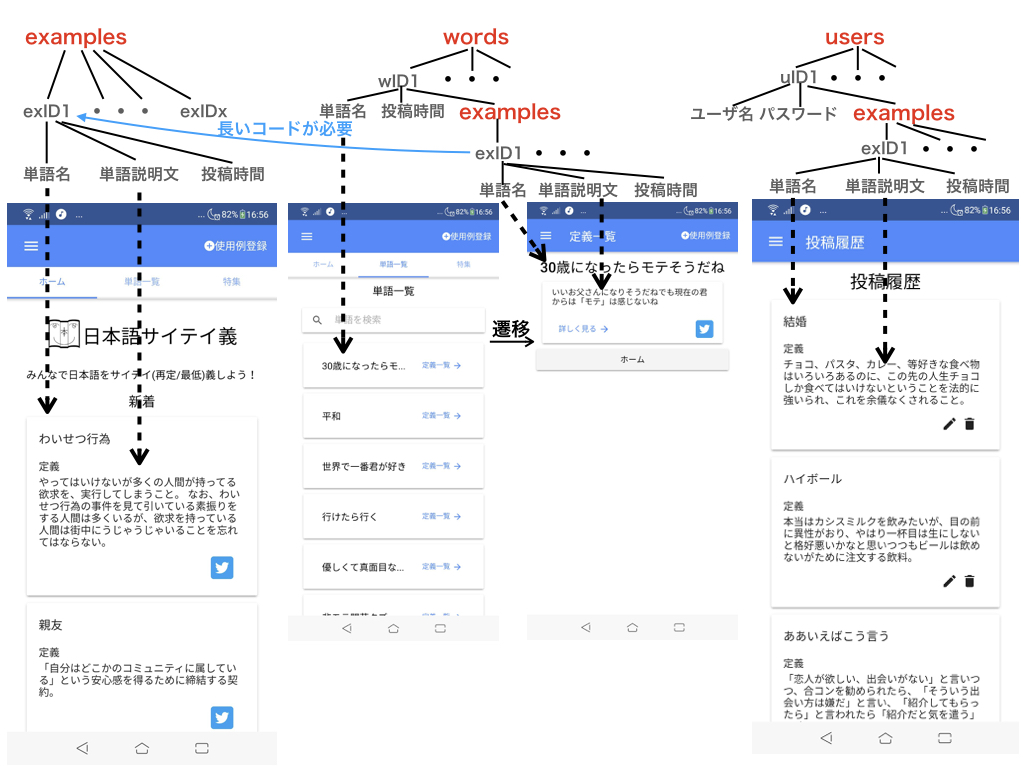
フォルダの中に、ファイルをぶちこんでいくようなイメージです。
このアプリでは、トップの階層に、examples、users、wordsのフォルダがあります。
Firestoreでは、このフォルダのような役割を持つものをコレクションと呼びます。
図中の赤文字がコレクションです。コレクションの下の階層にコレクションを作ることもできます。
図を見てわかるように、examplesコレクションが3つもあります。
すべてのexamplesコレクションには、同じデータが入ってます。
なぜこんな構成にしたかというと、別階層のコレクションの中の値を取ろうとすると、
ソースが長くなるからです。
一方、同じ階層下のコレクションの値は簡単に取れます。
上の図の、単語一覧画面は、wordsコレクションの中の値を表示してます。
単語一覧画面から、単語説明文画面に遷移する際に、examplesコレクションの
値が必要になります。
この際、
wordsコレクションの階層下のexamplesコレクションの中身の値を取る
という処理は簡単にかけるのですが、
wordsコレクションの階層下にあるexIDを用いて、トップ階層にあるexamplesコレクションの中身の値を取る
というリレーショナルなとり方をしようとすると、ソースコードは結構長くなってしまうんです。
このため、できるだけコレクションをまたがったデータの取得は避け、冗長なDBにしました。
トップ画面は、examplesコレクションだけを見れば描画でき、
単語一覧画面と単語説明文画面は、wordsコレクションだけを見れば描画でき、
投稿履歴画面は、usersコレクションだけを見れば描画できる。
とにかく、ビューに合わせたDB設計にしました。
冗長なので、書き込みは遅くなりますが、ユーザにとっては読み込み速度の方が
大事といえます。
また、頭の中がぐちゃぐちゃになりやすい僕にとって、
ソースコードや全体の設計の把握のしやすさが重要でした。
「このページを描画するときは、このコレクションから全部とってくればOK」という認識でやれば
頭の中がキレイに整理されます。
Cloud Firestoreの使い方の最適解かはわかりませんが、僕はこれでいい感じにできました。
詳しくは公式ドキュメントをみてください。
データモデルの説明はこちらです。